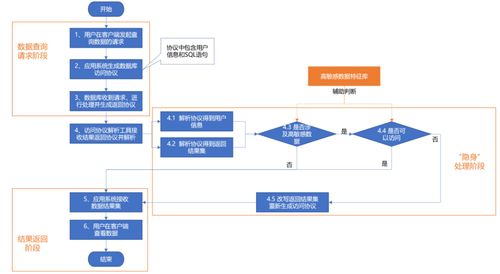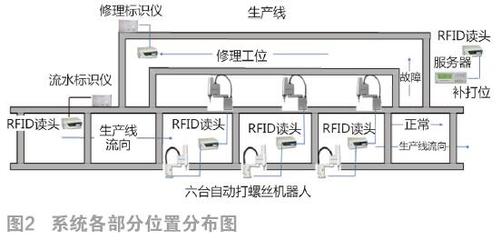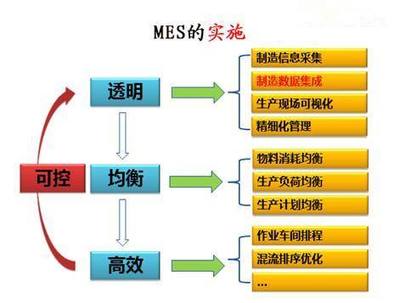
在當今數據驅動的時代,數據處理是信息提取、分析和決策制定的基石。這一過程往往伴隨著諸多挑戰,如數據質量低下、處理效率不足、工具選擇困難等。本文將探討數據處理過程中的常見問題,并提供一系列行之有效的解決辦法。
一、 數據質量問題及解決辦法
數據質量是分析結果可靠性的前提。常見問題包括數據缺失、數據不一致、數據重復和異常值。
- 數據缺失:對于少量缺失,可使用均值、中位數或眾數進行填充;對于分類變量,可建立預測模型進行填補;若缺失比例過高,需評估是否保留該字段。
- 數據不一致:建立統一的數據標準和清洗規則,如日期格式標準化、單位統一、命名規范等,并利用腳本或ETL工具自動化執行。
- 數據重復:使用去重算法(如基于關鍵字段匹配)識別并合并或刪除重復記錄。
- 異常值:通過統計方法(如3σ原則)或可視化方法識別異常值,并根據業務邏輯判斷是修正、保留還是剔除。
二、 處理效率與性能優化
面對海量數據,處理速度至關重要。
- 增量處理:避免全量重跑,只處理新增或變更的數據。
- 并行與分布式計算:利用Hadoop、Spark等框架,將任務拆分到多個節點并行執行。
- 算法與查詢優化:選擇時間復雜度更低的算法;對數據庫查詢建立索引,優化SQL語句。
- 資源管理:合理分配計算和存儲資源,使用內存計算或緩存中間結果以減少I/O開銷。
三、 工具與流程的合理選擇
合適的工具能事半功倍。
- 明確需求:根據數據量、處理復雜度、團隊技能和預算選擇工具,輕量級任務可用Python(Pandas)、R,大數據場景則需專業平臺。
- 構建標準化流程:建立從數據接入、清洗、轉換到加載(ETL/ELT)的標準化流水線,提高可維護性和可重復性。
- 版本控制與文檔化:對數據處理代碼和流程使用Git等工具進行版本管理,并詳細記錄數據血緣和轉換邏輯,確保過程可追溯。
四、 安全與合規性保障
處理數據時必須考慮隱私和安全。
- 數據脫敏與加密:對敏感信息(如身份證號、手機號)進行脫敏或加密處理,尤其在測試和開發環境。
- 權限管控:實施嚴格的基于角色的訪問控制(RBAC),確保只有授權人員能接觸特定數據。
- 遵守法規:確保數據處理流程符合GDPR、個人信息保護法等法律法規的要求。
五、 團隊協作與知識管理
數據處理常是團隊協作的結果。
- 代碼復用與模塊化:將常用清洗、轉換函數模塊化,建立團隊共享的工具庫。
- 持續監控與預警:對數據處理作業的成功率、運行時長、數據質量指標進行監控,設置異常預警。
- 培養數據素養:提升團隊成員的數據處理能力和質量意識,形成規范的操作習慣。
高效的數據處理并非一蹴而就,它需要一個結合了清晰策略、合適工具、嚴謹流程和團隊協作的系統性方法。通過預見性地應對質量、效率、工具和安全等方面的挑戰,并實施上述解決辦法,組織可以構建出穩健、可靠且可擴展的數據處理能力,從而為深度分析和價值挖掘奠定堅實的基礎。